Demo
Demo · Encode
Usage · Encode
-
Select file (Input): Click Select file to choose the source file to encode (text/image/video, etc.). A preview appears at the right (image/video/text first 30 lines).
-
Select algorithm (Encode Method → Algorithm): Choose from DNA Fountain / Yin–Yang Codec / Derrick / PolarCode / Hedges.
-
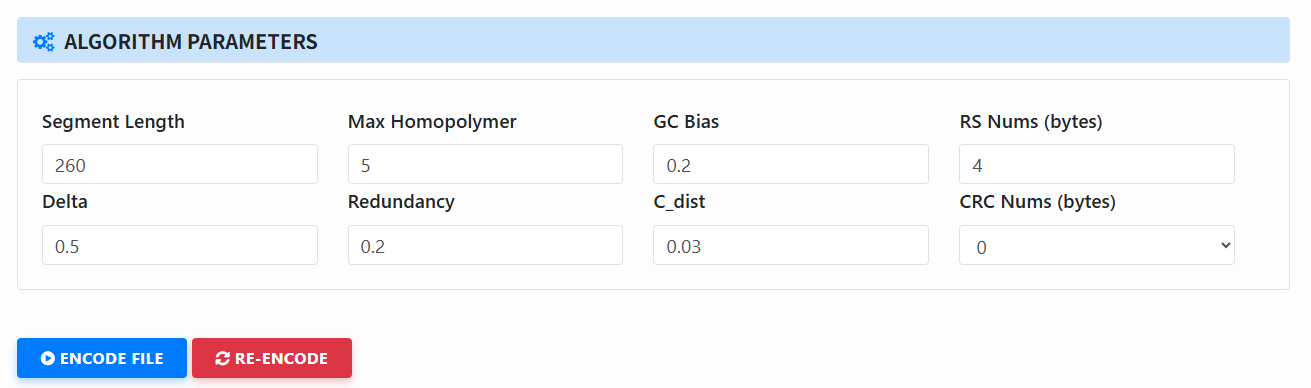
Fill in parameters (Algorithm Parameters): The page will show the parameter block for the selected algorithm (only parameters relevant to this algorithm appear). Adjust as needed.
-
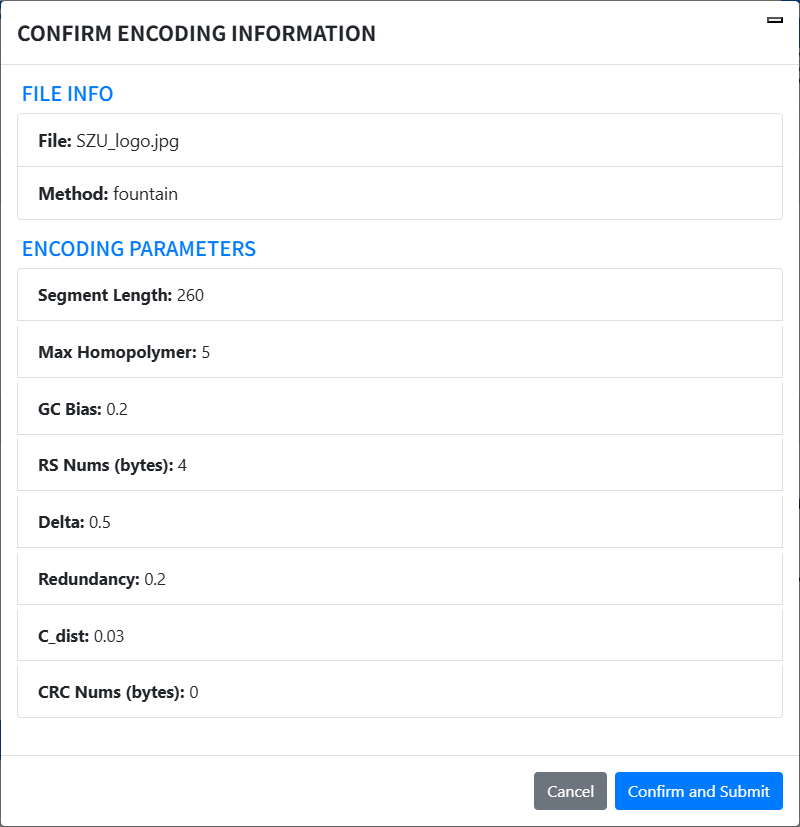
Start encoding: Click Encode File... A modal will pop up asking you to confirm the chosen settings. Verify and click Confirm and Submit.
-
View results (Output): After encoding, a result panel appears (method, total bits/bases, time, number of sequences, information density, max homopolymer length, etc.). Click download to download the encoded FASTA.
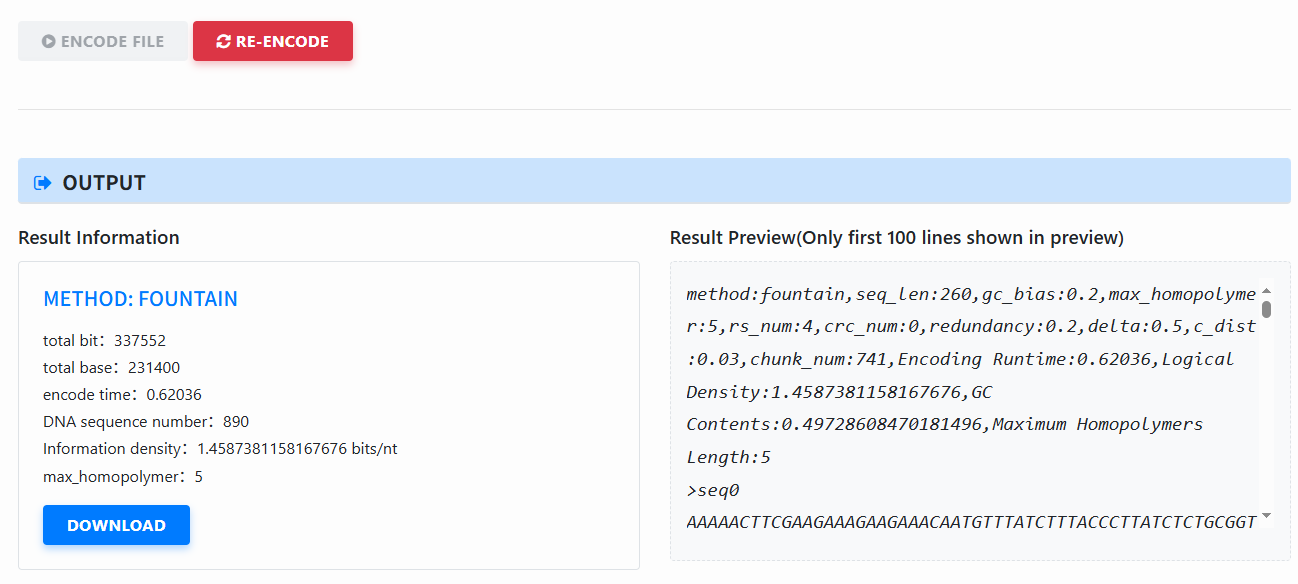
-
Re-encode: Click Re-encode (right-side button) to reset the page, then change parameters or file and encode again.
Tips:
- Avoid very large files to keep the subsequent simulate step manageable.
- For DNA Fountain on small files, consider a larger redundancy.
- When encoding starts, a confirmation modal (showing file name and parameters) appears. Click Confirm and Submit to begin; the progress bar starts at 0%.
- To retest with new parameters, use the Re-encode button on the right to reset.
Demo · Simulate
Usage · Simulate
-
Choose pipeline steps (Simulation Steps): Check the stages to simulate (Synthesis is always on; optional Decay / PCR / Sampling / Sequencing), then click OK.

-
Select input file (Input): By default, use the FASTA/FA file from the previous Encode step; you can also select a new file (preview shows the first 100 lines).
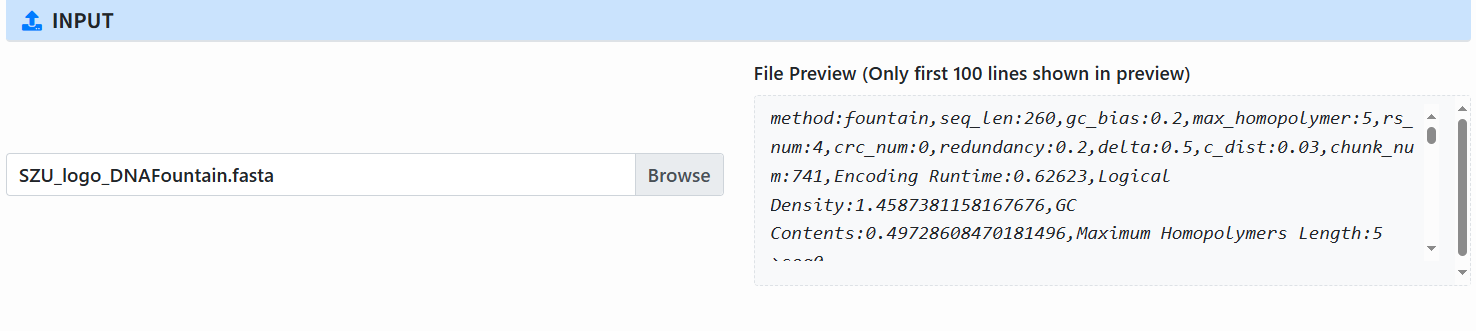
-
Configure parameters for each module: The page shows parameter blocks for selected steps:
- Synthesis: Per oligo scale, Multiple of sample
- Decay: Years, Decay ratio, Temperature, Humidity
- PCR: PCR cycles, PCR probability
- Sampling: Sampling ratio
- Sequencing: Sequencing method, Sequencing depth
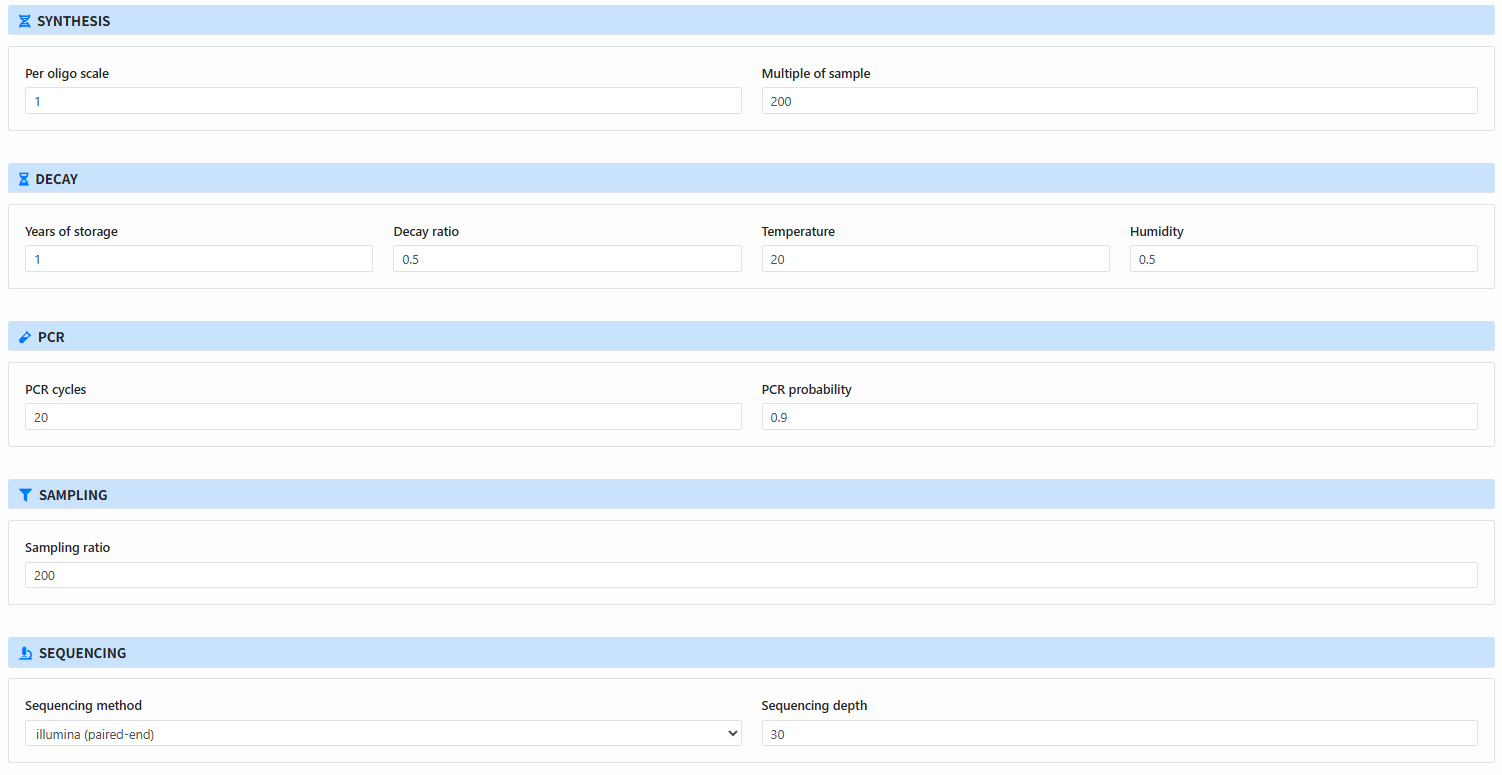
-
Start simulation: Click start simulate (a confirmation modal appears). Verify File Info / Steps / Parameters and click Confirm & Submit to start the progress bar.
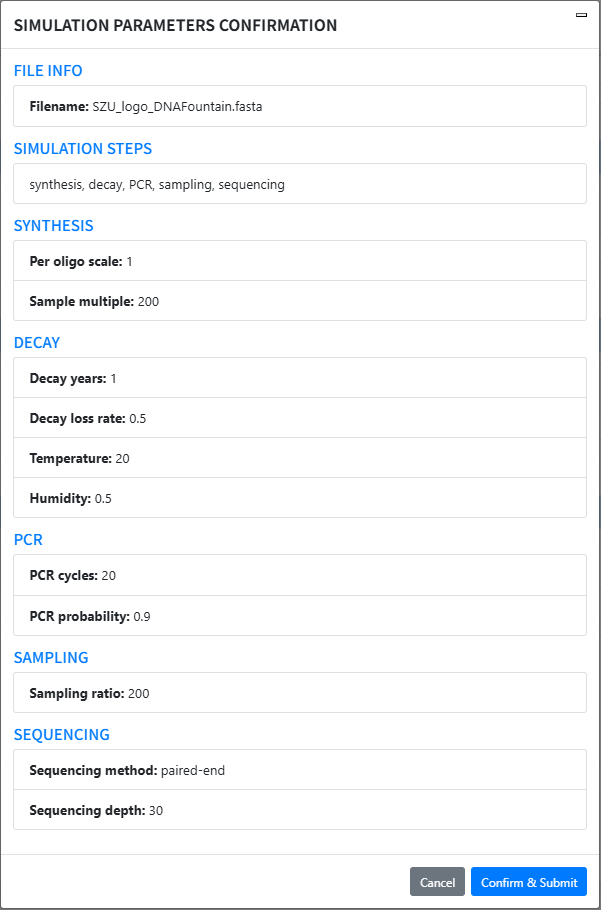
-
View & download results: After completion, see elapsed time in the result card and click download to get the generated sequencing files/results.
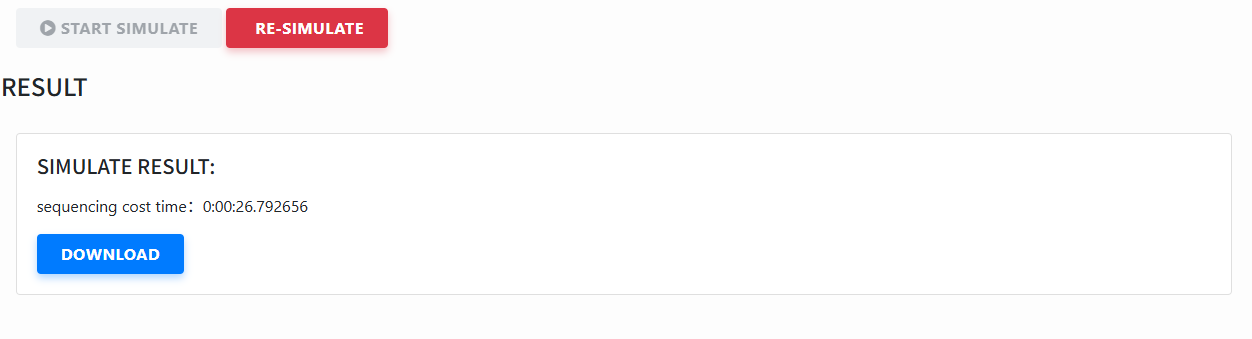
- Re-simulate: Click Re-simulate to reset and run with different steps or parameters.
Tips:
- If a step is not selected, its parameter block will not appear and it will be skipped.
- To reuse the previous Encode output, keep the default file; otherwise select a new FASTA/FA.
- If you choose to simulate long-read (third-gen) sequencing, it will take longer.
Demo · Decode
Usage · Decode
-
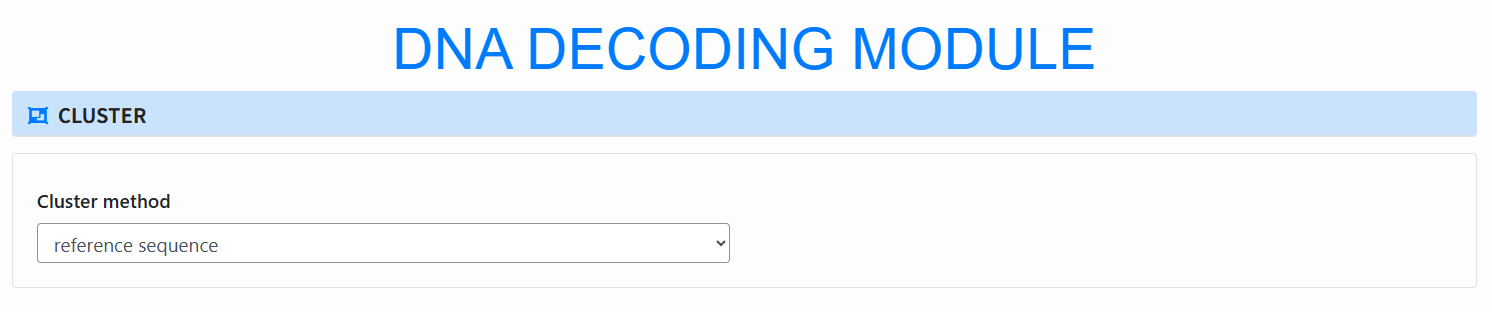
Select clustering method (Cluster): In the Cluster method dropdown choose:
- index: index-based clustering (set Index length);
- reference sequence: clustering via reference sequence; requires the Encode output (auto-filled if you encoded earlier);
- I don't need cluster: skip clustering.
- Note: if no simulation was run, you do not need clustering and reconstruction.
-
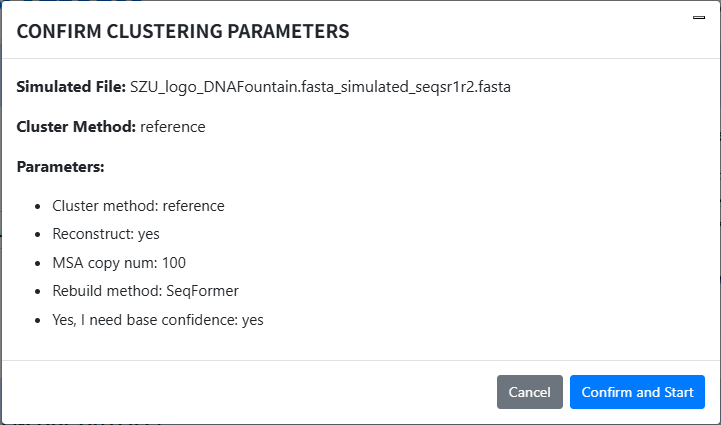
Set reconstruction parameters (Reconstruct):
- Choose whether to use consensus for decoding (yes/no).
- Set MSA copy num.
- If reconstructing, choose Rebuild method (SeqFormer, bsalign, BMALA, DivBMA, Hybrid, Iterative, etc.).
- Optional Base confidence (per-base confidence/quality for soft decoding).
- Note: reconstruction uses MSA to recover the original encoded sequence from reads (Derrick always requires reconstruction).

-
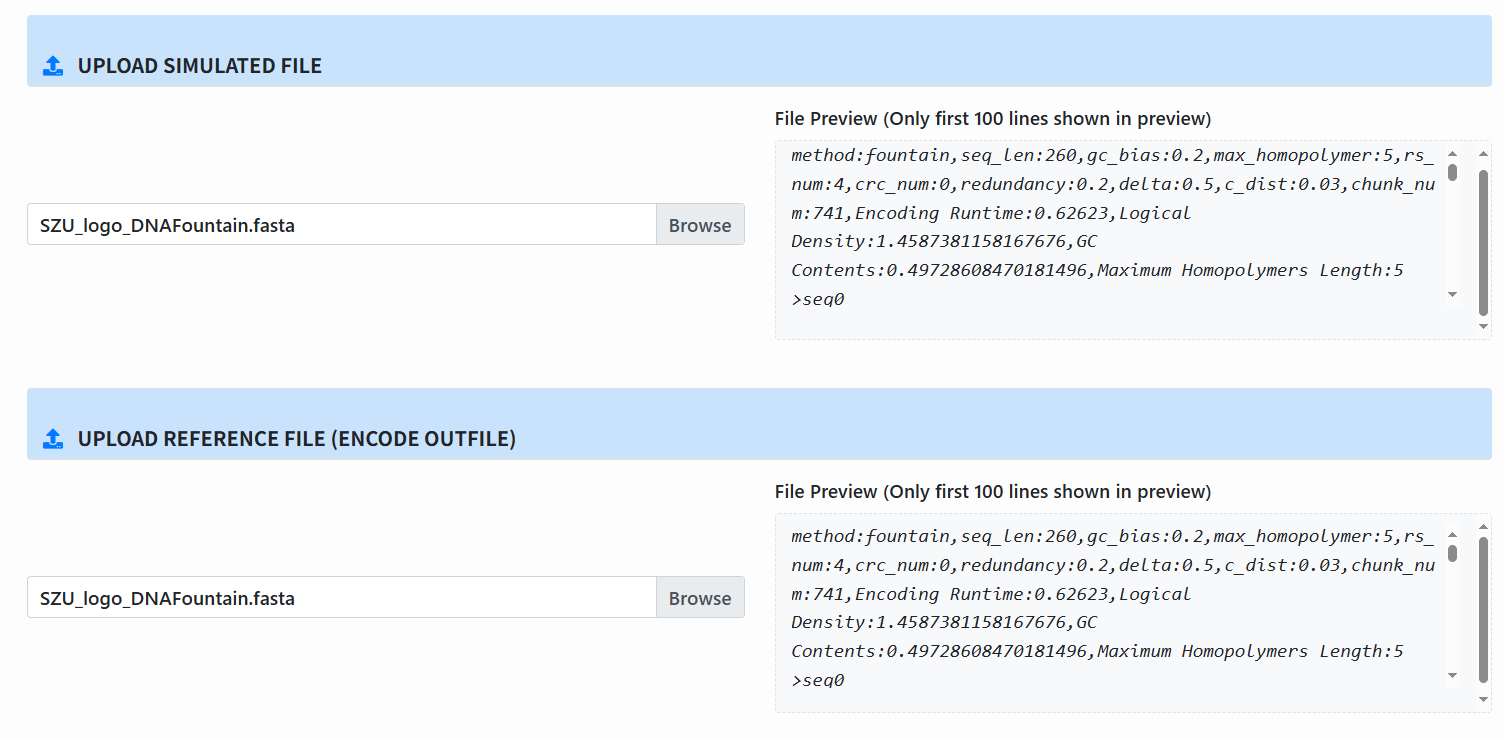
Upload files:
- Simulated File: output from the simulation.
- Reference File: the encoded reference file.
-
Run clustering: Click Cluster Start, a confirmation dialog appears; confirm to run clustering.
-
Upload files for decoding (enabled only after clustering completes):
- Decode File: the clustering output.
- Origin File: the original input file, used for final comparison.
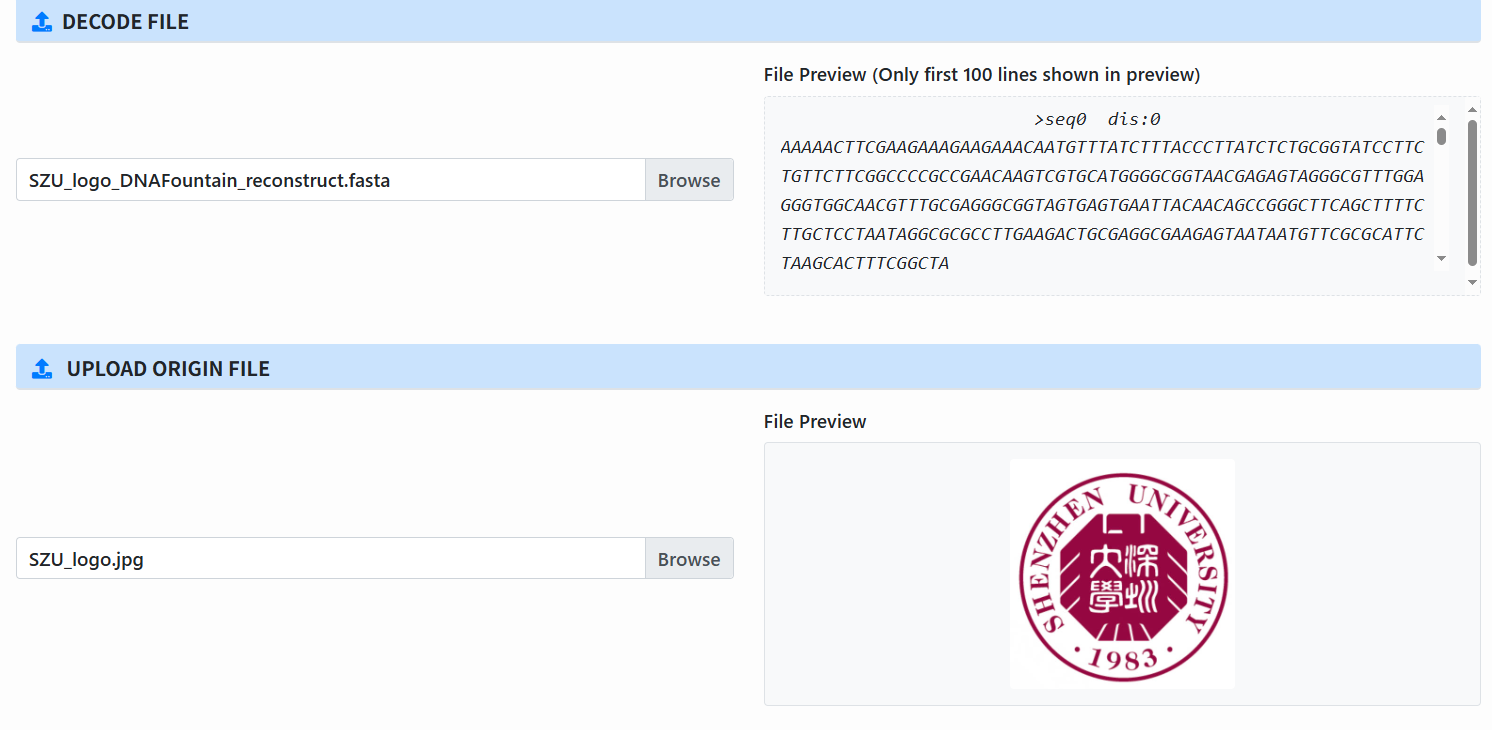
-
Select decoding method (Decode Method):
- Algorithm: DNA Fountain, YYC, Derrick, Hedges.
- Decision: choose Hard or Soft (Soft only when Reconstruct=yes and Base confidence=yes).

-
Set decoding parameters (Decode Settings):
- Max Copy Num: number of sequences per cluster to use for decoding, which can only be used if no reconstruct is done

-
View decoding results:
- Elapsed time, bad bits, total bits, recovery rate, etc.
- Download Decode Result and Evaluation indicators (for the evaluate module).
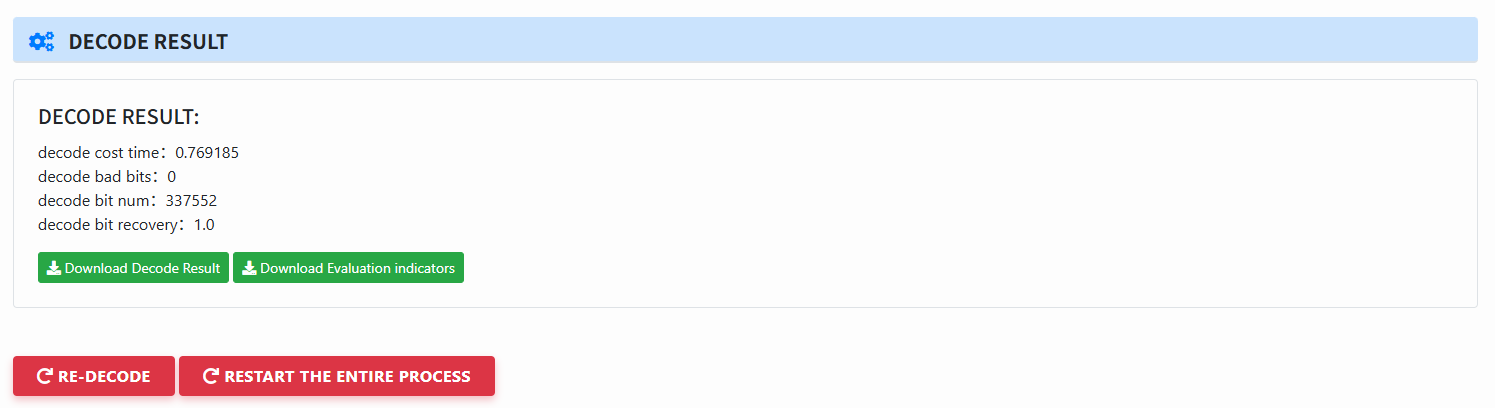
-
Do it again:
- Re-cluster: run clustering again.
- Re-decode: run decoding again.
- Restart the entire process: start over from the beginning.
Tips:
- Derrick always requires reconstruction.
- Soft Decision requires Reconstruct = yes and Base confidence = yes.
- The decoding algorithm must be consistent with the encoding algorithm.
- For Hedges, it’s better to set a smaller Max Copy Num, otherwise decoding can be very slow.
Demo · Evaluate
Usage · Evaluate
-
Upload CSV files:
Each row represents one experiment or one method.
Required columns (case-insensitive/aliases allowed):
Method,Filename, and any of the following numeric columns:Costs,Sequencing Depth Requirement,Encoding Runtime,Decoding Runtime,Physical Ratio,Logical Ratio,GC Contents,Maximum Homopolymers Length,File Recovery. -
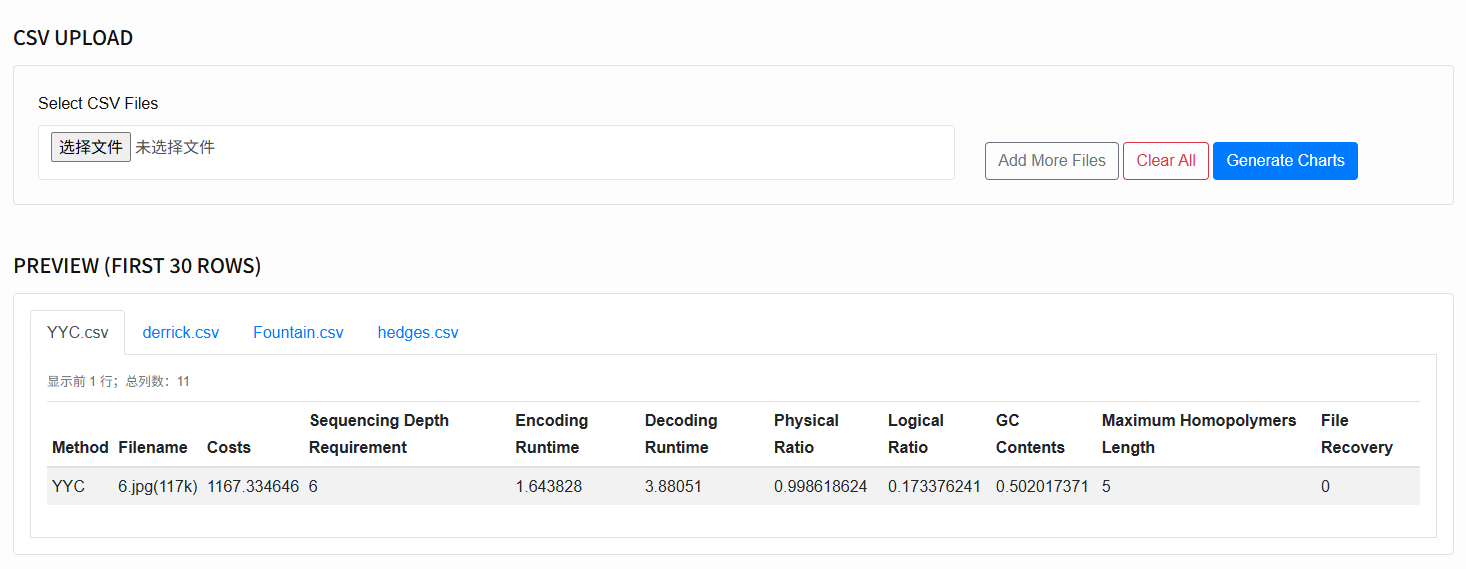
Select files (CSV Upload):
Click Select CSV Files to choose one or more CSVs.
To append, click Add More Files; to clear, click Clear All.

- Preview: After selection, the system parses and shows the first 30 rows of each CSV so you can verify column names and formats.
-
Evaluation mode:
Two comparison modes are supported:
- Same Method, Different Files — compare the same method across multiple files.
- Same File, Different Methods — compare multiple methods on the same file.
-
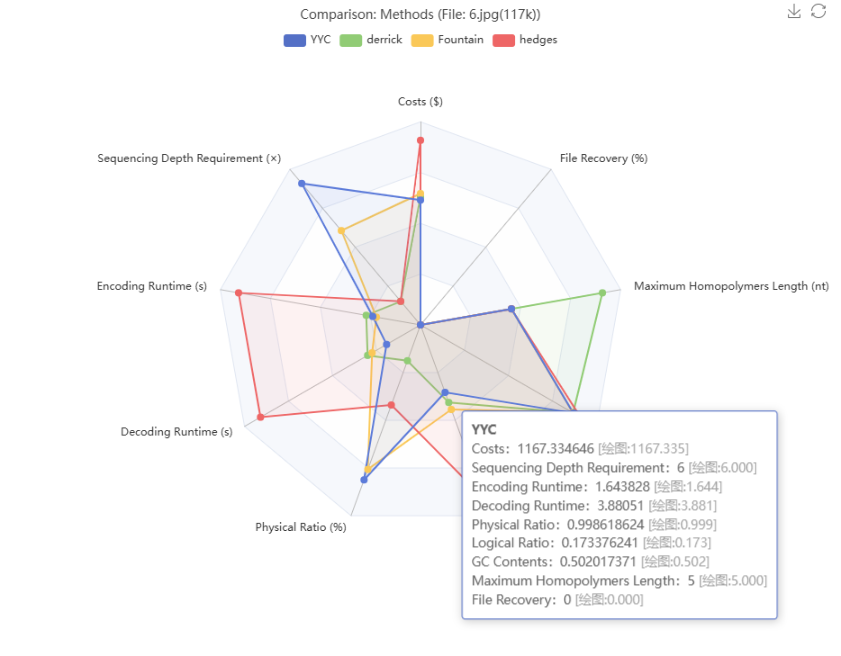
Generate charts:
Click Generate Charts. The system merges valid data according to the chosen mode and renders a
radar chart for performance comparison across methods or files.
-
Read the charts:
Toggle methods/files via the legend; hover to view exact metric values.
The tooltip displays both the raw mean and the normalized value used for plotting.
Each metric is normalized against its own maximum to avoid scale bias.
- Import again: When changing data, use Clear All to reset, or continue with Add More Files to add new files.
- The two comparison modes are: (1) same file with different methods; (2) different files with the same method.
- You can zoom the radar chart with the mouse wheel.
- Hovering over a metric shows the original value.
Tips: